Жаропонижающие средства для детей назначаются педиатром. Но бывают ситуации неотложной помощи при лихорадке, когда ребенку нужно дать лекарство немедленно. Тогда родители берут на себя ответственность и применяют жаропонижающие препараты. Что разрешено давать детям грудного возраста? Чем можно сбить температуру у детей постарше? Какие лекарства самые безопасные?
Метод наименьших квадратов (МНК, англ. Ordinary Least Squares, OLS ) -- математический метод, применяемый для решения различных задач, основанный на минимизации суммы квадратов отклонений некоторых функций от искомых переменных. Он может использоваться для «решения» переопределенных систем уравнений (когда количество уравнений превышает количество неизвестных), для поиска решения в случае обычных (не переопределенных) нелинейных систем уравнений, для аппроксимации точечных значений некоторой функцией. МНК является одним из базовых методов регрессионного анализа для оценки неизвестных параметров регрессионных моделей по выборочным данным.
Сущность метода наименьших квадратов
Пусть -- набор неизвестных переменных (параметров), -- совокупность функций от этого набора переменных. Задача заключается в подборе таких значений x, чтобы значения этих функций были максимально близки к некоторым значениям. По существу речь идет о «решении» переопределенной системы уравнений в указанном смысле максимальной близости левой и правой частей системы. Сущность МНК заключается в выборе в качестве «меры близости» суммы квадратов отклонений левых и правых частей -- . Таким образом, сущность МНК может быть выражена следующим образом:
В случае, если система уравнений имеет решение, то минимум суммы квадратов будет равен нулю и могут быть найдены точные решения системы уравнений аналитически или, например, различными численными методами оптимизации. Если система переопределена, то есть, говоря нестрого, количество независимых уравнений больше количества искомых переменных, то система не имеет точного решения и метод наименьших квадратов позволяет найти некоторый «оптимальный» вектор в смысле максимальной близости векторов и или максимальной близости вектора отклонений к нулю (близость понимается в смысле евклидова расстояния).
Пример -- система линейных уравнений
В частности, метод наименьших квадратов может использоваться для «решения» системы линейных уравнений
где матрица не квадратная, а прямоугольная размера (точнее ранг матрицы A больше количества искомых переменных).
Такая система уравнений, в общем случае не имеет решения. Поэтому эту систему можно «решить» только в смысле выбора такого вектора, чтобы минимизировать «расстояние» между векторами и. Для этого можно применить критерий минимизации суммы квадратов разностей левой и правой частей уравнений системы, то есть. Нетрудно показать, что решение этой задачи минимизации приводит к решению следующей системы уравнений
Используя оператор псевдоинверсии, решение можно переписать так:
где -- псевдообратная матрица для.
Данную задачу также можно «решить» используя так называемый взвешенный МНК (см. ниже), когда разные уравнения системы получают разный вес из теоретических соображений.
Строгое обоснование и установление границ содержательной применимости метода даны А. А. Марковым и А. Н. Колмогоровым.
МНК в регрессионном анализе (аппроксимация данных)[править | править вики-текст] Пусть имеется значений некоторой переменной (это могут быть результаты наблюдений, экспериментов и т. д.) и соответствующих переменных. Задача заключается в том, чтобы взаимосвязь между и аппроксимировать некоторой функцией, известной с точностью до некоторых неизвестных параметров, то есть фактически найти наилучшие значения параметров, максимально приближающие значения к фактическим значениям. Фактически это сводится к случаю «решения» переопределенной системы уравнений относительно:
В регрессионном анализе и в частности в эконометрике используются вероятностные модели зависимости между переменными
где -- так называемые случайные ошибки модели.
Соответственно, отклонения наблюдаемых значений от модельных предполагается уже в самой модели. Сущность МНК (обычного, классического) заключается в том, чтобы найти такие параметры, при которых сумма квадратов отклонений (ошибок, для регрессионных моделей их часто называют остатками регрессии) будет минимальной:
где -- англ. Residual Sum of Squares определяется как:
В общем случае решение этой задачи может осуществляться численными методами оптимизации (минимизации). В этом случае говорят о нелинейном МНК (NLS или NLLS -- англ. Non-Linear Least Squares). Во многих случаях можно получить аналитическое решение. Для решения задачи минимизации необходимо найти стационарные точки функции, продифференцировав её по неизвестным параметрам, приравняв производные к нулю и решив полученную систему уравнений:

МНК в случае линейной регрессии[править | править вики-текст]
Пусть регрессионная зависимость является линейной:

Пусть y -- вектор-столбец наблюдений объясняемой переменной, а -- это -матрица наблюдений факторов (строки матрицы -- векторы значений факторов в данном наблюдении, по столбцам -- вектор значений данного фактора во всех наблюдениях). Матричное представление линейной модели имеет вид:
Тогда вектор оценок объясняемой переменной и вектор остатков регрессии будут равны
соответственно сумма квадратов остатков регрессии будет равна
Дифференцируя эту функцию по вектору параметров и приравняв производные к нулю, получим систему уравнений (в матричной форме):
В расшифрованной матричной форме эта система уравнений выглядит следующим образом:

где все суммы берутся по всем допустимым значениям.
Если в модель включена константа (как обычно), то при всех, поэтому в левом верхнем углу матрицы системы уравнений находится количество наблюдений, а в остальных элементах первой строки и первого столбца -- просто суммы значений переменных: и первый элемент правой части системы -- .
Решение этой системы уравнений и дает общую формулу МНК-оценок для линейной модели:
Для аналитических целей оказывается полезным последнее представление этой формулы (в системе уравнений при делении на n, вместо сумм фигурируют средние арифметические). Если в регрессионной модели данные центрированы, то в этом представлении первая матрица имеет смысл выборочной ковариационной матрицы факторов, а вторая -- вектор ковариаций факторов с зависимой переменной. Если кроме того данные ещё инормированы на СКО (то есть в конечном итоге стандартизированы), то первая матрица имеет смысл выборочной корреляционной матрицы факторов, второй вектор -- вектора выборочных корреляций факторов с зависимой переменной.
Немаловажное свойство МНК-оценок для моделей с константой -- линия построенной регрессии проходит через центр тяжести выборочных данных, то есть выполняется равенство:

В частности, в крайнем случае, когда единственным регрессором является константа, получаем, что МНК-оценка единственного параметра (собственно константы) равна среднему значению объясняемой переменной. То есть среднее арифметическое, известное своими хорошими свойствами из законов больших чисел, также является МНК-оценкой -- удовлетворяет критерию минимума суммы квадратов отклонений от неё.
Простейшие частные случаи[править | править вики-текст]
В случае парной линейной регрессии, когда оценивается линейная зависимость одной переменной от другой, формулы расчета упрощаются (можно обойтись без матричной алгебры). Система уравнений имеет вид:
Отсюда несложно найти оценки коэффициентов:

Несмотря на то что в общем случае модели с константой предпочтительней, в некоторых случаях из теоретических соображений известно, что константа должна быть равна нулю. Например, в физике зависимость между напряжением и силой тока имеет вид; замеряя напряжение и силу тока, необходимо оценить сопротивление. В таком случае речь идёт о модели. В этом случае вместо системы уравнений имеем единственное уравнение
Следовательно, формула оценки единственного коэффициента имеет вид
Статистические свойства МНК-оценок[править | править вики-текст]
В первую очередь, отметим, что для линейных моделей МНК-оценки являются линейными оценками, как это следует из вышеприведённой формулы. Длянесмещенности МНК-оценок необходимо и достаточно выполнения важнейшего условия регрессионного анализа: условное по факторам математическое ожидание случайной ошибки должно быть равно нулю. Данное условие, в частности, выполнено, если математическое ожидание случайных ошибок равно нулю, и факторы и случайные ошибки -- независимые случайные величины.
Первое условие можно считать выполненным всегда для моделей с константой, так как константа берёт на себя ненулевое математическое ожидание ошибок (поэтому модели с константой в общем случае предпочтительнее). наименьший квадрат регрессионный ковариационный
Второе условие -- условие экзогенности факторов -- принципиальное. Если это свойство не выполнено, то можно считать, что практически любые оценки будут крайне неудовлетворительными: они не будут даже состоятельными (то есть даже очень большой объём данных не позволяет получить качественные оценки в этом случае). В классическом случае делается более сильное предположение о детерминированности факторов, в отличие от случайной ошибки, что автоматически означает выполнение условия экзогенности. В общем случае для состоятельности оценок достаточно выполнения условия экзогенности вместе со сходимостью матрицы к некоторой невырожденной матрице при увеличении объёма выборки до бесконечности.
Для того, чтобы кроме состоятельности и несмещенности, оценки (обычного) МНК были ещё и эффективными (наилучшими в классе линейных несмещенных оценок) необходимо выполнение дополнительных свойств случайной ошибки:
Постоянная (одинаковая) дисперсия случайных ошибок во всех наблюдениях (отсутствие гетероскедастичности):
Отсутствие корреляции (автокорреляции) случайных ошибок в разных наблюдениях между собой
Данные предположения можно сформулировать для ковариационной матрицы вектора случайных ошибок
Линейная модель, удовлетворяющая таким условиям, называется классической. МНК-оценки для классической линейной регрессии являютсянесмещёнными, состоятельными и наиболее эффективными оценками в классе всех линейных несмещённых оценок (в англоязычной литературе иногда употребляют аббревиатуру BLUE (Best Linear Unbiased Estimator) -- наилучшая линейная несмещённая оценка; в отечественной литературе чаще приводится теорема Гаусса -- Маркова). Как нетрудно показать, ковариационная матрица вектора оценок коэффициентов будет равна:
Эффективность означает, что эта ковариационная матрица является «минимальной» (любая линейная комбинация коэффициентов, и в частности сами коэффициенты, имеют минимальную дисперсию), то есть в классе линейных несмещенных оценок оценки МНК-наилучшие. Диагональные элементы этой матрицы -- дисперсии оценок коэффициентов -- важные параметры качества полученных оценок. Однако рассчитать ковариационную матрицу невозможно, поскольку дисперсия случайных ошибок неизвестна. Можно доказать, что несмещённой и состоятельной (для классической линейной модели) оценкой дисперсии случайных ошибок является величина:
Подставив данное значение в формулу для ковариационной матрицы и получим оценку ковариационной матрицы. Полученные оценки также являютсянесмещёнными и состоятельными. Важно также то, что оценка дисперсии ошибок (а значит и дисперсий коэффициентов) и оценки параметров модели являются независимыми случайными величинами, что позволяет получить тестовые статистики для проверки гипотез о коэффициентах модели.
Необходимо отметить, что если классические предположения не выполнены, МНК-оценки параметров не являются наиболее эффективными оценками (оставаясь несмещёнными и состоятельными). Однако, ещё более ухудшается оценка ковариационной матрицы -- она становится смещённой инесостоятельной. Это означает, что статистические выводы о качестве построенной модели в таком случае могут быть крайне недостоверными. Одним из вариантов решения последней проблемы является применение специальных оценок ковариационной матрицы, которые являются состоятельными при нарушениях классических предположений (стандартные ошибки в форме Уайта и стандартные ошибки в форме Ньюи-Уеста). Другой подход заключается в применении так называемого обобщённого МНК.
Обобщенный МНК[править | править вики-текст]
Основная статья: Обобщенный метод наименьших квадратов
Метод наименьших квадратов допускает широкое обобщение. Вместо минимизации суммы квадратов остатков можно минимизировать некоторую положительно определенную квадратичную форму от вектора остатков, где -- некоторая симметрическая положительно определенная весовая матрица. Обычный МНК является частным случаем данного подхода, когда весовая матрица пропорциональна единичной матрице. Как известно из теории симметрических матриц (или операторов) для таких матриц существует разложение. Следовательно, указанный функционал можно представить следующим образом
то есть этот функционал можно представить как сумму квадратов некоторых преобразованных «остатков». Таким образом, можно выделить класс методов наименьших квадратов -- LS-методы (Least Squares).
Доказано (теорема Айткена), что для обобщенной линейной регрессионной модели (в которой на ковариационную матрицу случайных ошибок не налагается никаких ограничений) наиболее эффективными (в классе линейных несмещенных оценок) являются оценки т. н. обобщенного МНК (ОМНК, GLS -- Generalized Least Squares) -- LS-метода с весовой матрицей, равной обратной ковариационной матрице случайных ошибок: .
Можно показать, что формула ОМНК-оценок параметров линейной модели имеет вид
Ковариационная матрица этих оценок соответственно будет равна
Фактически сущность ОМНК заключается в определенном (линейном) преобразовании (P) исходных данных и применении обычного МНК к преобразованным данным. Цель этого преобразования -- для преобразованных данных случайные ошибки уже удовлетворяют классическим предположениям.
Взвешенный МНК[править | править вики-текст]
В случае диагональной весовой матрицы (а значит и ковариационной матрицы случайных ошибок) имеем так называемый взвешенный МНК (WLS -- Weighted Least Squares). В данном случае минимизируется взвешенная сумма квадратов остатков модели, то есть каждое наблюдение получает «вес», обратно пропорциональный дисперсии случайной ошибки в данном наблюдении:

Фактически данные преобразуются взвешиванием наблюдений (делением на величину, пропорциональную предполагаемому стандартному отклонению случайных ошибок), а к взвешенным данным применяется обычный МНК.
Которое находит самое широкое применение в различных областях науки и практической деятельности. Это может быть физика, химия, биология, экономика, социология, психология и так далее, так далее. Волею судьбы мне часто приходится иметь дело с экономикой, и поэтому сегодня я оформлю вам путёвку в удивительную страну под названием Эконометрика =) …Как это не хотите?! Там очень хорошо – нужно только решиться! …Но вот то, что вы, наверное, определённо хотите – так это научиться решать задачи методом наименьших квадратов . И особо прилежные читатели научатся решать их не только безошибочно, но ещё и ОЧЕНЬ БЫСТРО;-) Но сначала общая постановка задачи + сопутствующий пример:
Пусть в некоторой предметной области исследуются показатели , которые имеют количественное выражение. При этом есть все основания полагать, что показатель зависит от показателя . Это полагание может быть как научной гипотезой, так и основываться на элементарном здравом смысле. Оставим, однако, науку в сторонке и исследуем более аппетитные области – а именно, продовольственные магазины. Обозначим через:
– торговую площадь продовольственного магазина, кв.м.,
– годовой товарооборот продовольственного магазина, млн. руб.
Совершенно понятно, что чем больше площадь магазина, тем в большинстве случаев будет больше его товарооборот.
Предположим, что после проведения наблюдений/опытов/подсчётов/танцев с бубном в нашем распоряжении оказываются числовые данные:
С гастрономами, думаю, всё понятно: – это площадь 1-го магазина, – его годовой товарооборот, – площадь 2-го магазина, – его годовой товарооборот и т.д. Кстати, совсем не обязательно иметь доступ к секретным материалам – довольно точную оценку товарооборота можно получить средствами математической статистики
. Впрочем, не отвлекаемся, курс коммерческого шпионажа – он уже платный =)
Табличные данные также можно записать в виде точек и изобразить в привычной для нас декартовой системе .
Ответим на важный вопрос: сколько точек нужно для качественного исследования?
Чем больше, тем лучше. Минимально допустимый набор состоит из 5-6 точек. Кроме того, при небольшом количестве данных в выборку нельзя включать «аномальные» результаты. Так, например, небольшой элитный магазин может выручать на порядки больше «своих коллег», искажая тем самым общую закономерность, которую и требуется найти!
Если совсем просто – нам нужно подобрать функцию , график
которой проходит как можно ближе к точкам ![]() . Такую функцию называют аппроксимирующей
(аппроксимация – приближение)
или теоретической функцией
. Вообще говоря, тут сразу появляется очевидный «претендент» – многочлен высокой степени, график которого проходит через ВСЕ точки. Но этот вариант сложен, а зачастую и просто некорректен (т.к. график будет всё время «петлять» и плохо отражать главную тенденцию)
.
. Такую функцию называют аппроксимирующей
(аппроксимация – приближение)
или теоретической функцией
. Вообще говоря, тут сразу появляется очевидный «претендент» – многочлен высокой степени, график которого проходит через ВСЕ точки. Но этот вариант сложен, а зачастую и просто некорректен (т.к. график будет всё время «петлять» и плохо отражать главную тенденцию)
.
Таким образом, разыскиваемая функция должна быть достаточно простА и в то же время отражать зависимость адекватно. Как вы догадываетесь, один из методов нахождения таких функций и называется методом наименьших квадратов
. Сначала разберём его суть в общем виде. Пусть некоторая функция приближает экспериментальные данные :
Как оценить точность данного приближения? Вычислим и разности (отклонения) между экспериментальными и функциональными значениями (изучаем чертёж)
. Первая мысль, которая приходит в голову – это оценить, насколько великА сумма , но проблема состоит в том, что разности могут быть и отрицательны (например, ![]() )
и отклонения в результате такого суммирования будут взаимоуничтожаться. Поэтому в качестве оценки точности приближения напрашивается принять сумму модулей
отклонений:
)
и отклонения в результате такого суммирования будут взаимоуничтожаться. Поэтому в качестве оценки точности приближения напрашивается принять сумму модулей
отклонений:
![]() или в свёрнутом виде: (вдруг кто не знает: – это значок суммы, а – вспомогательная переменная-«счётчик», которая принимает значения от 1 до )
.
или в свёрнутом виде: (вдруг кто не знает: – это значок суммы, а – вспомогательная переменная-«счётчик», которая принимает значения от 1 до )
.
Приближая экспериментальные точки различными функциями, мы будем получать разные значения , и очевидно, где эта сумма меньше – та функция и точнее.
Такой метод существует и называется он методом наименьших модулей . Однако на практике получил гораздо бОльшее распространение метод наименьших квадратов , в котором возможные отрицательные значения ликвидируются не модулем, а возведением отклонений в квадрат:
![]() , после чего усилия направлены на подбор такой функции , чтобы сумма квадратов отклонений
, после чего усилия направлены на подбор такой функции , чтобы сумма квадратов отклонений ![]() была как можно меньше. Собственно, отсюда и название метода.
была как можно меньше. Собственно, отсюда и название метода.
И сейчас мы возвращаемся к другому важному моменту: как отмечалось выше, подбираемая функция должна быть достаточно простА – но ведь и таких функций тоже немало: линейная , гиперболическая , экспоненциальная , логарифмическая , квадратичная и т.д. И, конечно же, тут сразу бы хотелось «сократить поле деятельности». Какой класс функций выбрать для исследования? Примитивный, но эффективный приём:
– Проще всего изобразить точки ![]() на чертеже и проанализировать их расположение. Если они имеют тенденцию располагаться по прямой, то следует искать уравнение прямой
на чертеже и проанализировать их расположение. Если они имеют тенденцию располагаться по прямой, то следует искать уравнение прямой
![]() с оптимальными значениями и . Иными словами, задача состоит в нахождении ТАКИХ коэффициентов – чтобы сумма квадратов отклонений была наименьшей.
с оптимальными значениями и . Иными словами, задача состоит в нахождении ТАКИХ коэффициентов – чтобы сумма квадратов отклонений была наименьшей.
Если же точки расположены, например, по гиперболе
, то заведомо понятно, что линейная функция будет давать плохое приближение. В этом случае ищем наиболее «выгодные» коэффициенты для уравнения гиперболы ![]() – те, которые дают минимальную сумму квадратов
– те, которые дают минимальную сумму квадратов  .
.
А теперь обратите внимание, что в обоих случаях речь идёт о функции двух переменных
, аргументами которой являются параметры разыскиваемых зависимостей
:
И по существу нам требуется решить стандартную задачу – найти минимум функции двух переменных .
Вспомним про наш пример: предположим, что «магазинные» точки имеют тенденцию располагаться по прямой линии и есть все основания полагать наличие линейной зависимости
товарооборота от торговой площади. Найдём ТАКИЕ коэффициенты «а» и «бэ», чтобы сумма квадратов отклонений ![]() была наименьшей. Всё как обычно – сначала частные производные 1-го порядка
. Согласно правилу линейности
дифференцировать можно прямо под значком суммы:
была наименьшей. Всё как обычно – сначала частные производные 1-го порядка
. Согласно правилу линейности
дифференцировать можно прямо под значком суммы:
Если хотите использовать данную информацию для реферата или курсовика – буду очень благодарен за поставленную ссылку в списке источников, такие подробные выкладки найдёте мало где:
Составим стандартную систему:
Сокращаем каждое уравнение на «двойку» и, кроме того, «разваливаем» суммы:
Примечание
: самостоятельно проанализируйте, почему «а» и «бэ» можно вынести за значок суммы. Кстати, формально это можно проделать и с суммой
![]()
Перепишем систему в «прикладном» виде:
после чего начинает прорисовываться алгоритм решения нашей задачи:
Координаты точек мы знаем? Знаем. Суммы ![]() найти можем? Легко. Составляем простейшую систему двух линейных уравнений с двумя неизвестными
(«а» и «бэ»). Систему решаем, например, методом Крамера
, в результате чего получаем стационарную точку . Проверяя достаточное условие экстремума
, можно убедиться, что в данной точке функция
найти можем? Легко. Составляем простейшую систему двух линейных уравнений с двумя неизвестными
(«а» и «бэ»). Систему решаем, например, методом Крамера
, в результате чего получаем стационарную точку . Проверяя достаточное условие экстремума
, можно убедиться, что в данной точке функция ![]() достигает именно минимума
. Проверка сопряжена с дополнительными выкладками и поэтому оставим её за кадром (при необходимости недостающий кадр можно посмотреть )
. Делаем окончательный вывод:
достигает именно минимума
. Проверка сопряжена с дополнительными выкладками и поэтому оставим её за кадром (при необходимости недостающий кадр можно посмотреть )
. Делаем окончательный вывод:
Функция ![]() наилучшим образом (по крайне мере, по сравнению с любой другой линейной функцией)
приближает экспериментальные точки
наилучшим образом (по крайне мере, по сравнению с любой другой линейной функцией)
приближает экспериментальные точки ![]() . Грубо говоря, её график проходит максимально близко к этим точкам. В традициях эконометрики
полученную аппроксимирующую функцию также называют уравнением пАрной линейной регрессии
.
. Грубо говоря, её график проходит максимально близко к этим точкам. В традициях эконометрики
полученную аппроксимирующую функцию также называют уравнением пАрной линейной регрессии
.
Рассматриваемая задача имеет большое практическое значение. В ситуации с нашим примером, уравнение ![]() позволяет прогнозировать, какой товарооборот («игрек»)
будет у магазина при том или ином значении торговой площади (том или ином значении «икс»)
. Да, полученный прогноз будет лишь прогнозом, но во многих случаях он окажется достаточно точным.
позволяет прогнозировать, какой товарооборот («игрек»)
будет у магазина при том или ином значении торговой площади (том или ином значении «икс»)
. Да, полученный прогноз будет лишь прогнозом, но во многих случаях он окажется достаточно точным.
Я разберу всего лишь одну задачу с «реальными» числами, поскольку никаких трудностей в ней нет – все вычисления на уровне школьной программы 7-8 класса. В 95 процентов случаев вам будет предложено отыскать как раз линейную функцию, но в самом конце статьи я покажу, что ничуть не сложнее отыскать уравнения оптимальной гиперболы, экспоненты и некоторых других функций.
По сути, осталось раздать обещанные плюшки – чтобы вы научились решать такие примеры не только безошибочно, но ещё и быстро. Внимательно изучаем стандарт:
Задача
В результате исследования взаимосвязи двух показателей, получены следующие пары чисел:
Методом наименьших квадратов найти линейную функцию, которая наилучшим образом приближает эмпирические (опытные)
данные. Сделать чертеж, на котором в декартовой прямоугольной системе координат построить экспериментальные точки и график аппроксимирующей функции ![]() . Найти сумму квадратов отклонений между эмпирическими и теоретическими значениями. Выяснить, будет ли функция лучше (с точки зрения метода наименьших квадратов)
приближать экспериментальные точки.
. Найти сумму квадратов отклонений между эмпирическими и теоретическими значениями. Выяснить, будет ли функция лучше (с точки зрения метода наименьших квадратов)
приближать экспериментальные точки.
Заметьте, что «иксовые» значения – натуральные, и это имеет характерный содержательный смысл, о котором я расскажу чуть позже; но они, разумеется, могут быть и дробными. Кроме того, в зависимости от содержания той или иной задачи как «иксовые», так и «игрековые» значения полностью или частично могут быть отрицательными. Ну а у нас дана «безликая» задача, и мы начинаем её решение :
Коэффициенты оптимальной функции найдём как решение системы:
В целях более компактной записи переменную-«счётчик» можно опустить, поскольку и так понятно, что суммирование осуществляется от 1 до .
Расчёт нужных сумм удобнее оформить в табличном виде:
Вычисления можно провести на микрокалькуляторе, но гораздо лучше использовать Эксель – и быстрее, и без ошибок; смотрим короткий видеоролик:
Таким образом, получаем следующую систему
:![]()
Тут можно умножить второе уравнение на 3 и из 1-го уравнения почленно вычесть 2-е
. Но это везение – на практике системы чаще не подарочны, и в таких случаях спасает метод Крамера
:
, значит, система имеет единственное решение.

Выполним проверку. Понимаю, что не хочется, но зачем же пропускать ошибки там, где их можно стопроцентно не пропустить? Подставим найденное решение в левую часть каждого уравнения системы:
Получены правые части соответствующих уравнений, значит, система решена правильно.
Таким образом, искомая аппроксимирующая функция: – из всех линейных функций экспериментальные данные наилучшим образом приближает именно она.
В отличие от прямой
зависимости товарооборота магазина от его площади, найденная зависимость является обратной
(принцип «чем больше – тем меньше»)
, и этот факт сразу выявляется по отрицательному угловому коэффициенту
. Функция ![]() сообщает нам о том, что с увеличение некоего показателя на 1 единицу значение зависимого показателя уменьшается в среднем
на 0,65 единиц. Как говорится, чем выше цена на гречку, тем меньше её продано.
сообщает нам о том, что с увеличение некоего показателя на 1 единицу значение зависимого показателя уменьшается в среднем
на 0,65 единиц. Как говорится, чем выше цена на гречку, тем меньше её продано.
Для построения графика аппроксимирующей функции найдём два её значения:
и выполним чертёж:
Построенная прямая называется линией тренда
(а именно – линией линейного тренда, т.е. в общем случае тренд – это не обязательно прямая линия)
. Всем знакомо выражение «быть в тренде», и, думаю, что этот термин не нуждается в дополнительных комментариях.
Вычислим сумму квадратов отклонений ![]() между эмпирическими и теоретическими значениями. Геометрически – это сумма квадратов длин «малиновых» отрезков (два из которых настолько малы, что их даже не видно)
.
между эмпирическими и теоретическими значениями. Геометрически – это сумма квадратов длин «малиновых» отрезков (два из которых настолько малы, что их даже не видно)
.
Вычисления сведём в таблицу:
Их можно опять же провести вручную, на всякий случай приведу пример для 1-й точки:![]()
но намного эффективнее поступить уже известным образом:
Еще раз повторим: в чём смысл полученного результата?
Из всех линейных функций
у функции ![]() показатель является наименьшим, то есть в своём семействе это наилучшее приближение. И здесь, кстати, не случаен заключительный вопрос задачи: а вдруг предложенная экспоненциальная функция
показатель является наименьшим, то есть в своём семействе это наилучшее приближение. И здесь, кстати, не случаен заключительный вопрос задачи: а вдруг предложенная экспоненциальная функция ![]() будет лучше приближать экспериментальные точки?
будет лучше приближать экспериментальные точки?
Найдем соответствующую сумму квадратов отклонений – чтобы различать, я обозначу их буквой «эпсилон». Техника точно такая же:
И снова на всякий пожарный вычисления для 1-й точки:
В Экселе пользуемся стандартной функцией EXP
(синтаксис можно посмотреть в экселевской Справке)
.
Вывод
: , значит, экспоненциальная функция приближает экспериментальные точки хуже, чем прямая ![]() .
.
Но тут следует отметить, что «хуже» – это ещё не значит
, что плохо. Сейчас построил график этой экспоненциальной функции – и он тоже проходит близко к точкам ![]() – да так, что без аналитического исследования и сказать трудно, какая функция точнее.
– да так, что без аналитического исследования и сказать трудно, какая функция точнее.
На этом решение закончено, и я возвращаюсь к вопросу о натуральных значениях аргумента. В различных исследованиях, как правило, экономических или социологических, натуральными «иксами» нумеруют месяцы, годы или иные равные временнЫе промежутки. Рассмотрим, например, такую задачу.
Метод наименьших квадратов (МНК, англ. Ordinary Least Squares, OLS ) - математический метод, применяемый для решения различных задач, основанный на минимизации суммы квадратов отклонений некоторых функций от искомых переменных. Он может использоваться для «решения» переопределенных систем уравнений (когда количество уравнений превышает количество неизвестных), для поиска решения в случае обычных (не переопределенных) нелинейных систем уравнений, для аппроксимации точечных значений некоторой функции. МНК является одним из базовых методов регрессионного анализа для оценки неизвестных параметров регрессионных моделей по выборочным данным.
Энциклопедичный YouTube
1 / 5
✪ Метод наименьших квадратов. Тема
✪ Метод наименьших квадратов, урок 1/2. Линейная функция
✪ Эконометрика. Лекция 5 .Метод наименьших квадратов
✪ Митин И. В. - Обработка результатов физ. эксперимента - Метод наименьших квадратов (Лекция 4)
✪ Эконометрика: Суть метода наименьших квадратов #2
Субтитры
История
До начала XIX в. учёные не имели определённых правил для решения системы уравнений , в которой число неизвестных меньше, чем число уравнений; до этого времени употреблялись частные приёмы, зависевшие от вида уравнений и от остроумия вычислителей, и потому разные вычислители, исходя из тех же данных наблюдений, приходили к различным выводам. Гауссу (1795) принадлежит первое применение метода, а Лежандр (1805) независимо открыл и опубликовал его под современным названием (фр. Méthode des moindres quarrés ) . Лаплас связал метод с теорией вероятностей , а американский математик Эдрейн (1808) рассмотрел его теоретико-вероятностные приложения . Метод распространён и усовершенствован дальнейшими изысканиями Энке , Бесселя , Ганзена и других.
Сущность метода наименьших квадратов
Пусть x {\displaystyle x} - набор n {\displaystyle n} неизвестных переменных (параметров), f i (x) {\displaystyle f_{i}(x)} , , m > n {\displaystyle m>n} - совокупность функций от этого набора переменных. Задача заключается в подборе таких значений x {\displaystyle x} , чтобы значения этих функций были максимально близки к некоторым значениям y i {\displaystyle y_{i}} . По существу речь идет о «решении» переопределенной системы уравнений f i (x) = y i {\displaystyle f_{i}(x)=y_{i}} , i = 1 , … , m {\displaystyle i=1,\ldots ,m} в указанном смысле максимальной близости левой и правой частей системы. Сущность МНК заключается в выборе в качестве «меры близости» суммы квадратов отклонений левых и правых частей | f i (x) − y i | {\displaystyle |f_{i}(x)-y_{i}|} . Таким образом, сущность МНК может быть выражена следующим образом:
∑ i e i 2 = ∑ i (y i − f i (x)) 2 → min x {\displaystyle \sum _{i}e_{i}^{2}=\sum _{i}(y_{i}-f_{i}(x))^{2}\rightarrow \min _{x}} .В случае, если система уравнений имеет решение, то минимум суммы квадратов будет равен нулю и могут быть найдены точные решения системы уравнений аналитически или, например, различными численными методами оптимизации. Если система переопределена, то есть, говоря нестрого, количество независимых уравнений больше количества искомых переменных, то система не имеет точного решения и метод наименьших квадратов позволяет найти некоторый «оптимальный» вектор x {\displaystyle x} в смысле максимальной близости векторов y {\displaystyle y} и f (x) {\displaystyle f(x)} или максимальной близости вектора отклонений e {\displaystyle e} к нулю (близость понимается в смысле евклидова расстояния).
Пример - система линейных уравнений
В частности, метод наименьших квадратов может использоваться для «решения» системы линейных уравнений
A x = b {\displaystyle Ax=b} ,где A {\displaystyle A} прямоугольная матрица размера m × n , m > n {\displaystyle m\times n,m>n} (т.е. число строк матрицы A больше количества искомых переменных).
Такая система уравнений в общем случае не имеет решения. Поэтому эту систему можно «решить» только в смысле выбора такого вектора x {\displaystyle x} , чтобы минимизировать «расстояние» между векторами A x {\displaystyle Ax} и b {\displaystyle b} . Для этого можно применить критерий минимизации суммы квадратов разностей левой и правой частей уравнений системы, то есть (A x − b) T (A x − b) → min x {\displaystyle (Ax-b)^{T}(Ax-b)\rightarrow \min _{x}} . Нетрудно показать, что решение этой задачи минимизации приводит к решению следующей системы уравнений
A T A x = A T b ⇒ x = (A T A) − 1 A T b {\displaystyle A^{T}Ax=A^{T}b\Rightarrow x=(A^{T}A)^{-1}A^{T}b} .МНК в регрессионном анализе (аппроксимация данных)
Пусть имеется n {\displaystyle n} значений некоторой переменной y {\displaystyle y} (это могут быть результаты наблюдений, экспериментов и т. д.) и соответствующих переменных x {\displaystyle x} . Задача заключается в том, чтобы взаимосвязь между y {\displaystyle y} и x {\displaystyle x} аппроксимировать некоторой функцией , известной с точностью до некоторых неизвестных параметров b {\displaystyle b} , то есть фактически найти наилучшие значения параметров b {\displaystyle b} , максимально приближающие значения f (x , b) {\displaystyle f(x,b)} к фактическим значениям y {\displaystyle y} . Фактически это сводится к случаю «решения» переопределенной системы уравнений относительно b {\displaystyle b} :
F (x t , b) = y t , t = 1 , … , n {\displaystyle f(x_{t},b)=y_{t},t=1,\ldots ,n} .
В регрессионном анализе и в частности в эконометрике используются вероятностные модели зависимости между переменными
Y t = f (x t , b) + ε t {\displaystyle y_{t}=f(x_{t},b)+\varepsilon _{t}} ,
где ε t {\displaystyle \varepsilon _{t}} - так называемые случайные ошибки модели.
Соответственно, отклонения наблюдаемых значений y {\displaystyle y} от модельных f (x , b) {\displaystyle f(x,b)} предполагается уже в самой модели. Сущность МНК (обычного, классического) заключается в том, чтобы найти такие параметры b {\displaystyle b} , при которых сумма квадратов отклонений (ошибок, для регрессионных моделей их часто называют остатками регрессии) e t {\displaystyle e_{t}} будет минимальной:
b ^ O L S = arg min b R S S (b) {\displaystyle {\hat {b}}_{OLS}=\arg \min _{b}RSS(b)} ,где R S S {\displaystyle RSS} - англ. Residual Sum of Squares определяется как:
R S S (b) = e T e = ∑ t = 1 n e t 2 = ∑ t = 1 n (y t − f (x t , b)) 2 {\displaystyle RSS(b)=e^{T}e=\sum _{t=1}^{n}e_{t}^{2}=\sum _{t=1}^{n}(y_{t}-f(x_{t},b))^{2}} .В общем случае решение этой задачи может осуществляться численными методами оптимизации (минимизации). В этом случае говорят о нелинейном МНК (NLS или NLLS - англ. Non-Linear Least Squares ). Во многих случаях можно получить аналитическое решение. Для решения задачи минимизации необходимо найти стационарные точки функции R S S (b) {\displaystyle RSS(b)} , продифференцировав её по неизвестным параметрам b {\displaystyle b} , приравняв производные к нулю и решив полученную систему уравнений:
∑ t = 1 n (y t − f (x t , b)) ∂ f (x t , b) ∂ b = 0 {\displaystyle \sum _{t=1}^{n}(y_{t}-f(x_{t},b)){\frac {\partial f(x_{t},b)}{\partial b}}=0} .МНК в случае линейной регрессии
Пусть регрессионная зависимость является линейной:
y t = ∑ j = 1 k b j x t j + ε = x t T b + ε t {\displaystyle y_{t}=\sum _{j=1}^{k}b_{j}x_{tj}+\varepsilon =x_{t}^{T}b+\varepsilon _{t}} .Пусть y - вектор-столбец наблюдений объясняемой переменной, а X {\displaystyle X} - это (n × k) {\displaystyle ({n\times k})} -матрица наблюдений факторов (строки матрицы - векторы значений факторов в данном наблюдении, по столбцам - вектор значений данного фактора во всех наблюдениях). Матричное представление линейной модели имеет вид:
y = X b + ε {\displaystyle y=Xb+\varepsilon } .Тогда вектор оценок объясняемой переменной и вектор остатков регрессии будут равны
y ^ = X b , e = y − y ^ = y − X b {\displaystyle {\hat {y}}=Xb,\quad e=y-{\hat {y}}=y-Xb} .соответственно сумма квадратов остатков регрессии будет равна
R S S = e T e = (y − X b) T (y − X b) {\displaystyle RSS=e^{T}e=(y-Xb)^{T}(y-Xb)} .Дифференцируя эту функцию по вектору параметров b {\displaystyle b} и приравняв производные к нулю, получим систему уравнений (в матричной форме):
(X T X) b = X T y {\displaystyle (X^{T}X)b=X^{T}y} .В расшифрованной матричной форме эта система уравнений выглядит следующим образом:
(∑ x t 1 2 ∑ x t 1 x t 2 ∑ x t 1 x t 3 … ∑ x t 1 x t k ∑ x t 2 x t 1 ∑ x t 2 2 ∑ x t 2 x t 3 … ∑ x t 2 x t k ∑ x t 3 x t 1 ∑ x t 3 x t 2 ∑ x t 3 2 … ∑ x t 3 x t k ⋮ ⋮ ⋮ ⋱ ⋮ ∑ x t k x t 1 ∑ x t k x t 2 ∑ x t k x t 3 … ∑ x t k 2) (b 1 b 2 b 3 ⋮ b k) = (∑ x t 1 y t ∑ x t 2 y t ∑ x t 3 y t ⋮ ∑ x t k y t) , {\displaystyle {\begin{pmatrix}\sum x_{t1}^{2}&\sum x_{t1}x_{t2}&\sum x_{t1}x_{t3}&\ldots &\sum x_{t1}x_{tk}\\\sum x_{t2}x_{t1}&\sum x_{t2}^{2}&\sum x_{t2}x_{t3}&\ldots &\sum x_{t2}x_{tk}\\\sum x_{t3}x_{t1}&\sum x_{t3}x_{t2}&\sum x_{t3}^{2}&\ldots &\sum x_{t3}x_{tk}\\\vdots &\vdots &\vdots &\ddots &\vdots \\\sum x_{tk}x_{t1}&\sum x_{tk}x_{t2}&\sum x_{tk}x_{t3}&\ldots &\sum x_{tk}^{2}\\\end{pmatrix}}{\begin{pmatrix}b_{1}\\b_{2}\\b_{3}\\\vdots \\b_{k}\\\end{pmatrix}}={\begin{pmatrix}\sum x_{t1}y_{t}\\\sum x_{t2}y_{t}\\\sum x_{t3}y_{t}\\\vdots \\\sum x_{tk}y_{t}\\\end{pmatrix}},} где все суммы берутся по всем допустимым значениям t {\displaystyle t} .
Если в модель включена константа (как обычно), то x t 1 = 1 {\displaystyle x_{t1}=1} при всех t {\displaystyle t} , поэтому в левом верхнем углу матрицы системы уравнений находится количество наблюдений n {\displaystyle n} , а в остальных элементах первой строки и первого столбца - просто суммы значений переменных: ∑ x t j {\displaystyle \sum x_{tj}} и первый элемент правой части системы - ∑ y t {\displaystyle \sum y_{t}} .
Решение этой системы уравнений и дает общую формулу МНК-оценок для линейной модели:
b ^ O L S = (X T X) − 1 X T y = (1 n X T X) − 1 1 n X T y = V x − 1 C x y {\displaystyle {\hat {b}}_{OLS}=(X^{T}X)^{-1}X^{T}y=\left({\frac {1}{n}}X^{T}X\right)^{-1}{\frac {1}{n}}X^{T}y=V_{x}^{-1}C_{xy}} .Для аналитических целей оказывается полезным последнее представление этой формулы (в системе уравнений при делении на n, вместо сумм фигурируют средние арифметические). Если в регрессионной модели данные центрированы , то в этом представлении первая матрица имеет смысл выборочной ковариационной матрицы факторов, а вторая - вектор ковариаций факторов с зависимой переменной. Если кроме того данные ещё и нормированы на СКО (то есть в конечном итоге стандартизированы ), то первая матрица имеет смысл выборочной корреляционной матрицы факторов, второй вектор - вектора выборочных корреляций факторов с зависимой переменной.
Немаловажное свойство МНК-оценок для моделей с константой - линия построенной регрессии проходит через центр тяжести выборочных данных, то есть выполняется равенство:
y ¯ = b 1 ^ + ∑ j = 2 k b ^ j x ¯ j {\displaystyle {\bar {y}}={\hat {b_{1}}}+\sum _{j=2}^{k}{\hat {b}}_{j}{\bar {x}}_{j}} .В частности, в крайнем случае, когда единственным регрессором является константа, получаем, что МНК-оценка единственного параметра (собственно константы) равна среднему значению объясняемой переменной. То есть среднее арифметическое, известное своими хорошими свойствами из законов больших чисел, также является МНК-оценкой - удовлетворяет критерию минимума суммы квадратов отклонений от неё.
Простейшие частные случаи
В случае парной линейной регрессии y t = a + b x t + ε t {\displaystyle y_{t}=a+bx_{t}+\varepsilon _{t}} , когда оценивается линейная зависимость одной переменной от другой, формулы расчета упрощаются (можно обойтись без матричной алгебры). Система уравнений имеет вид:
(1 x ¯ x ¯ x 2 ¯) (a b) = (y ¯ x y ¯) {\displaystyle {\begin{pmatrix}1&{\bar {x}}\\{\bar {x}}&{\bar {x^{2}}}\\\end{pmatrix}}{\begin{pmatrix}a\\b\\\end{pmatrix}}={\begin{pmatrix}{\bar {y}}\\{\overline {xy}}\\\end{pmatrix}}} .Отсюда несложно найти оценки коэффициентов:
{ b ^ = Cov (x , y) Var (x) = x y ¯ − x ¯ y ¯ x 2 ¯ − x ¯ 2 , a ^ = y ¯ − b x ¯ . {\displaystyle {\begin{cases}{\hat {b}}={\frac {\mathop {\textrm {Cov}} (x,y)}{\mathop {\textrm {Var}} (x)}}={\frac {{\overline {xy}}-{\bar {x}}{\bar {y}}}{{\overline {x^{2}}}-{\overline {x}}^{2}}},\\{\hat {a}}={\bar {y}}-b{\bar {x}}.\end{cases}}}Несмотря на то что в общем случае модели с константой предпочтительней, в некоторых случаях из теоретических соображений известно, что константа a {\displaystyle a} должна быть равна нулю. Например, в физике зависимость между напряжением и силой тока имеет вид U = I ⋅ R {\displaystyle U=I\cdot R} ; замеряя напряжение и силу тока, необходимо оценить сопротивление. В таком случае речь идёт о модели y = b x {\displaystyle y=bx} . В этом случае вместо системы уравнений имеем единственное уравнение
(∑ x t 2) b = ∑ x t y t {\displaystyle \left(\sum x_{t}^{2}\right)b=\sum x_{t}y_{t}} .
Следовательно, формула оценки единственного коэффициента имеет вид
B ^ = ∑ t = 1 n x t y t ∑ t = 1 n x t 2 = x y ¯ x 2 ¯ {\displaystyle {\hat {b}}={\frac {\sum _{t=1}^{n}x_{t}y_{t}}{\sum _{t=1}^{n}x_{t}^{2}}}={\frac {\overline {xy}}{\overline {x^{2}}}}} .
Случай полиномиальной модели
Если данные аппроксимируются полиномиальной функцией регрессии одной переменной f (x) = b 0 + ∑ i = 1 k b i x i {\displaystyle f(x)=b_{0}+\sum \limits _{i=1}^{k}b_{i}x^{i}} , то, воспринимая степени x i {\displaystyle x^{i}} как независимые факторы для каждого i {\displaystyle i} можно оценить параметры модели исходя из общей формулы оценки параметров линейной модели. Для этого в общую формулу достаточно учесть, что при такой интерпретации x t i x t j = x t i x t j = x t i + j {\displaystyle x_{ti}x_{tj}=x_{t}^{i}x_{t}^{j}=x_{t}^{i+j}} и x t j y t = x t j y t {\displaystyle x_{tj}y_{t}=x_{t}^{j}y_{t}} . Следовательно, матричные уравнения в данном случае примут вид:
(n ∑ n x t … ∑ n x t k ∑ n x t ∑ n x t 2 … ∑ n x t k + 1 ⋮ ⋮ ⋱ ⋮ ∑ n x t k ∑ n x t k + 1 … ∑ n x t 2 k) [ b 0 b 1 ⋮ b k ] = [ ∑ n y t ∑ n x t y t ⋮ ∑ n x t k y t ] . {\displaystyle {\begin{pmatrix}n&\sum \limits _{n}x_{t}&\ldots &\sum \limits _{n}x_{t}^{k}\\\sum \limits _{n}x_{t}&\sum \limits _{n}x_{t}^{2}&\ldots &\sum \limits _{n}x_{t}^{k+1}\\\vdots &\vdots &\ddots &\vdots \\\sum \limits _{n}x_{t}^{k}&\sum \limits _{n}x_{t}^{k+1}&\ldots &\sum \limits _{n}x_{t}^{2k}\end{pmatrix}}{\begin{bmatrix}b_{0}\\b_{1}\\\vdots \\b_{k}\end{bmatrix}}={\begin{bmatrix}\sum \limits _{n}y_{t}\\\sum \limits _{n}x_{t}y_{t}\\\vdots \\\sum \limits _{n}x_{t}^{k}y_{t}\end{bmatrix}}.}
Статистические свойства МНК-оценок
В первую очередь, отметим, что для линейных моделей МНК-оценки являются линейными оценками, как это следует из вышеприведённой формулы. Для несмещенности МНК-оценок необходимо и достаточно выполнения важнейшего условия регрессионного анализа : условное по факторам математическое ожидание случайной ошибки должно быть равно нулю. Данное условие, в частности, выполнено, если
- математическое ожидание случайных ошибок равно нулю, и
- факторы и случайные ошибки - независимые случайные величины .
Второе условие - условие экзогенности факторов - принципиальное. Если это свойство не выполнено, то можно считать, что практически любые оценки будут крайне неудовлетворительными: они не будут даже состоятельными (то есть даже очень большой объём данных не позволяет получить качественные оценки в этом случае). В классическом случае делается более сильное предположение о детерминированности факторов, в отличие от случайной ошибки, что автоматически означает выполнение условия экзогенности. В общем случае для состоятельности оценок достаточно выполнения условия экзогенности вместе со сходимостью матрицы V x {\displaystyle V_{x}} к некоторой невырожденной матрице при увеличении объёма выборки до бесконечности.
Для того, чтобы кроме состоятельности и несмещенности , оценки (обычного) МНК были ещё и эффективными (наилучшими в классе линейных несмещенных оценок) необходимо выполнение дополнительных свойств случайной ошибки:
Данные предположения можно сформулировать для ковариационной матрицы вектора случайных ошибок V (ε) = σ 2 I {\displaystyle V(\varepsilon)=\sigma ^{2}I} .
Линейная модель, удовлетворяющая таким условиям, называется классической . МНК-оценки для классической линейной регрессии являются несмещёнными , состоятельными и наиболее эффективными оценками в классе всех линейных несмещённых оценок (в англоязычной литературе иногда употребляют аббревиатуру BLUE (Best Linear Unbiased Estimator ) - наилучшая линейная несмещённая оценка; в отечественной литературе чаще приводится теорема Гаусса - Маркова). Как нетрудно показать, ковариационная матрица вектора оценок коэффициентов будет равна:
V (b ^ O L S) = σ 2 (X T X) − 1 {\displaystyle V({\hat {b}}_{OLS})=\sigma ^{2}(X^{T}X)^{-1}} .
Эффективность означает, что эта ковариационная матрица является «минимальной» (любая линейная комбинация коэффициентов, и в частности сами коэффициенты, имеют минимальную дисперсию), то есть в классе линейных несмещенных оценок оценки МНК-наилучшие. Диагональные элементы этой матрицы - дисперсии оценок коэффициентов - важные параметры качества полученных оценок. Однако рассчитать ковариационную матрицу невозможно, поскольку дисперсия случайных ошибок неизвестна. Можно доказать, что несмещённой и состоятельной (для классической линейной модели) оценкой дисперсии случайных ошибок является величина:
S 2 = R S S / (n − k) {\displaystyle s^{2}=RSS/(n-k)} .
Подставив данное значение в формулу для ковариационной матрицы и получим оценку ковариационной матрицы. Полученные оценки также являются несмещёнными и состоятельными . Важно также то, что оценка дисперсии ошибок (а значит и дисперсий коэффициентов) и оценки параметров модели являются независимыми случайными величинами, что позволяет получить тестовые статистики для проверки гипотез о коэффициентах модели.
Необходимо отметить, что если классические предположения не выполнены, МНК-оценки параметров не являются наиболее эффективными и, где W {\displaystyle W} - некоторая симметрическая положительно определенная весовая матрица. Обычный МНК является частным случаем данного подхода, когда весовая матрица пропорциональна единичной матрице. Как известно, для симметрических матриц (или операторов) существует разложение W = P T P {\displaystyle W=P^{T}P} . Следовательно, указанный функционал можно представить следующим образом e T P T P e = (P e) T P e = e ∗ T e ∗ {\displaystyle e^{T}P^{T}Pe=(Pe)^{T}Pe=e_{*}^{T}e_{*}} , то есть этот функционал можно представить как сумму квадратов некоторых преобразованных «остатков». Таким образом, можно выделить класс методов наименьших квадратов - LS-методы (Least Squares).
Доказано (теорема Айткена), что для обобщенной линейной регрессионной модели (в которой на ковариационную матрицу случайных ошибок не налагается никаких ограничений) наиболее эффективными (в классе линейных несмещенных оценок) являются оценки т. н. обобщенного МНК (ОМНК, GLS - Generalized Least Squares) - LS-метода с весовой матрицей, равной обратной ковариационной матрице случайных ошибок: W = V ε − 1 {\displaystyle W=V_{\varepsilon }^{-1}} .
Можно показать, что формула ОМНК-оценок параметров линейной модели имеет вид
B ^ G L S = (X T V − 1 X) − 1 X T V − 1 y {\displaystyle {\hat {b}}_{GLS}=(X^{T}V^{-1}X)^{-1}X^{T}V^{-1}y} .
Ковариационная матрица этих оценок соответственно будет равна
V (b ^ G L S) = (X T V − 1 X) − 1 {\displaystyle V({\hat {b}}_{GLS})=(X^{T}V^{-1}X)^{-1}} .
Фактически сущность ОМНК заключается в определенном (линейном) преобразовании (P) исходных данных и применении обычного МНК к преобразованным данным. Цель этого преобразования - для преобразованных данных случайные ошибки уже удовлетворяют классическим предположениям.
Взвешенный МНК
В случае диагональной весовой матрицы (а значит и ковариационной матрицы случайных ошибок) имеем так называемый взвешенный МНК (WLS - Weighted Least Squares). В данном случае минимизируется взвешенная сумма квадратов остатков модели, то есть каждое наблюдение получает «вес», обратно пропорциональный дисперсии случайной ошибки в данном наблюдении: e T W e = ∑ t = 1 n e t 2 σ t 2 {\displaystyle e^{T}We=\sum _{t=1}^{n}{\frac {e_{t}^{2}}{\sigma _{t}^{2}}}} . Фактически данные преобразуются взвешиванием наблюдений (делением на величину, пропорциональную предполагаемому стандартному отклонению случайных ошибок), а к взвешенным данным применяется обычный МНК.
ISBN 978-5-7749-0473-0 .
Пример.
Экспериментальные данные о значениях переменных х
и у
приведены в таблице.
В результате их выравнивания получена функция ![]()
Используя метод наименьших квадратов , аппроксимировать эти данные линейной зависимостью y=ax+b (найти параметры а и b ). Выяснить, какая из двух линий лучше (в смысле метода наименьших квадратов) выравнивает экспериментальные данные. Сделать чертеж.
Суть метода наименьших квадратов (МНК).
Задача заключается в нахождении коэффициентов линейной зависимости, при которых функция двух переменных а
и b
![]() принимает наименьшее значение. То есть, при данных а
и b
сумма квадратов отклонений экспериментальных данных от найденной прямой будет наименьшей. В этом вся суть метода наименьших квадратов.
принимает наименьшее значение. То есть, при данных а
и b
сумма квадратов отклонений экспериментальных данных от найденной прямой будет наименьшей. В этом вся суть метода наименьших квадратов.
Таким образом, решение примера сводится к нахождению экстремума функции двух переменных.
Вывод формул для нахождения коэффициентов.
Составляется и решается система из двух уравнений с двумя неизвестными. Находим частные производные функции по переменным а
и b
, приравниваем эти производные к нулю.
Решаем полученную систему уравнений любым методом (например методом подстановки
или ) и получаем формулы для нахождения коэффициентов по методу наименьших квадратов (МНК).
При данных а
и b
функция ![]() принимает наименьшее значение. Доказательство этого факта приведено .
принимает наименьшее значение. Доказательство этого факта приведено .
Вот и весь метод наименьших квадратов. Формула для нахождения параметра a содержит суммы , , , и параметр n - количество экспериментальных данных. Значения этих сумм рекомендуем вычислять отдельно. Коэффициент b находится после вычисления a .
Пришло время вспомнить про исходый пример.
Решение.
В нашем примере n=5
. Заполняем таблицу для удобства вычисления сумм, которые входят в формулы искомых коэффициентов.
Значения в четвертой строке таблицы получены умножением значений 2-ой строки на значения 3-ей строки для каждого номера i .
Значения в пятой строке таблицы получены возведением в квадрат значений 2-ой строки для каждого номера i .
Значения последнего столбца таблицы – это суммы значений по строкам.
Используем формулы метода наименьших квадратов для нахождения коэффициентов а
и b
. Подставляем в них соответствующие значения из последнего столбца таблицы:
Следовательно, y = 0.165x+2.184 - искомая аппроксимирующая прямая.
Осталось выяснить какая из линий y = 0.165x+2.184
или ![]() лучше аппроксимирует исходные данные, то есть произвести оценку методом наименьших квадратов.
лучше аппроксимирует исходные данные, то есть произвести оценку методом наименьших квадратов.
Оценка погрешности метода наименьших квадратов.
Для этого требуется вычислить суммы квадратов отклонений исходных данных от этих линий ![]() и
и ![]() , меньшее значение соответствует линии, которая лучше в смысле метода наименьших квадратов аппроксимирует исходные данные.
, меньшее значение соответствует линии, которая лучше в смысле метода наименьших квадратов аппроксимирует исходные данные.
Так как , то прямая y = 0.165x+2.184 лучше приближает исходные данные.
Графическая иллюстрация метода наименьших квадратов (мнк).
На графиках все прекрасно видно. Красная линия – это найденная прямая y = 0.165x+2.184
, синяя линия – это ![]() , розовые точки – это исходные данные.
, розовые точки – это исходные данные.

Для чего это нужно, к чему все эти аппроксимации?
Я лично использую для решения задач сглаживания данных, задач интерполяции и экстраполяции (в исходном примере могли бы попросить найти занчение наблюдаемой величины y при x=3 или при x=6 по методу МНК). Но подробнее поговорим об этом позже в другом разделе сайта.
Доказательство.
Чтобы при найденных а
и b
функция принимала наименьшее значение, необходимо чтобы в этой точке матрица квадратичной формы дифференциала второго порядка для функции ![]() была положительно определенной. Покажем это.
была положительно определенной. Покажем это.
Дифференциал второго порядка имеет вид:
То есть
Следовательно, матрица квадратичной формы имеет вид
причем значения элементов не зависят от а
и b
.
Покажем, что матрица положительно определенная. Для этого нужно, чтобы угловые миноры были положительными.
Угловой минор первого порядка  . Неравенство строгое, так как точки несовпадающие. В дальнейшем это будем подразумевать.
. Неравенство строгое, так как точки несовпадающие. В дальнейшем это будем подразумевать.
Угловой минор второго порядка
Докажем, что  методом математической индукции .
методом математической индукции .

Вывод
: найденные значения а
и b
соответствуют наименьшему значению функции ![]() , следовательно, являются искомыми параметрами для метода наименьших квадратов.
, следовательно, являются искомыми параметрами для метода наименьших квадратов.
(см. рисунок). Требуется найти уравнение прямой
Чем меньше числа по абсолютной величине, тем лучше подобрана прямая (2). В качестве характеристики точности подбора прямой (2) можно принять сумму квадратов
Условия минимума S будут
 |
(6) |
 |
(7) |
Уравнения (6) и (7) можно записать в таком виде:
 |
(8) |
 |
(9) |
Из уравнений (8) и (9) легко найти a и b по опытным значениям x i и y i . Прямая (2), определяемая уравнениями (8) и (9), называется прямой, полученной по методу наименьших квадратов (этим названием подчеркивается то, что сумма квадратов S имеет минимум). Уравнения (8) и (9), из которых определяется прямая (2), называются нормальными уравнениями.
Можно указать простой и общий способ составления нормальных уравнений. Используя опытные точки (1) и уравнение (2), можно записать систему уравнений для a и b
| y 1 =ax 1 +b, | |||
| y 2 =ax 2 +b, ... |
(10) | ||
| y n =ax n +b, | |||
Умножим левую и правую части каждого из этих уравнений на коэффициент при первой неизвестной a (т.е. на x 1 , x 2 , ..., x n) и сложим полученные уравнения, в результате получится первое нормальное уравнение (8).
Умножим левую и правую части каждого из этих уравнений на коэффициент при второй неизвестной b, т.е. на 1, и сложим полученные уравнения, в результате получится второе нормальное уравнение (9).
Этот способ получения нормальных уравнений является общим: он пригоден, например, и для функции
есть величина постоянная и ее нужно определить по опытным данным (1).
Систему уравнений для k можно записать:
Найти прямую (2) по методу наименьших квадратов.
Решение. Находим:
x i =21, y i =46,3, x i 2 =91, x i y i =179,1.
Записываем уравнения (8) и (9)
Отсюда находим
Оценка точности метода наименьших квадратов
Дадим оценку точности метода для линейного случая, когда имеет место уравнение (2).
Пусть опытные значения x i являются точными, а опытные значения y i имеют случайные ошибки с одинаковой дисперсией для всех i.
Введем обозначение
| (16) |
Тогда решения уравнений (8) и (9) можно представить в виде
| (17) | |
| (18) | |
| где | |
| (19) | |
| Из уравнения (17) находим | |
| (20) | |
| Аналогично из уравнения (18) получаем | |
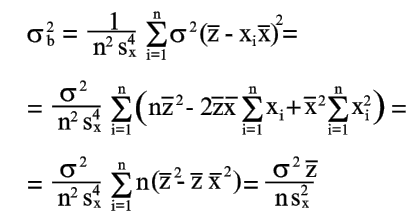 |
(21) |
| так как | |
| (22) | |
| Из уравнений (21) и (22) находим | |
 |
(23) |
Уравнения (20) и (23) дают оценку точности коэффициентов, определенных по уравнениям (8) и (9).
Заметим, что коэффициенты a и b коррелированы. Путем простых преобразований находим их корреляционный момент.
Отсюда находим
0,072 при x=1 и 6,
0,041 при x=3,5.
Литература
Шор. Я. Б. Статистические методы анализа и контроля качества и надежности. М.:Госэнергоиздат, 1962, с. 552, С. 92-98.
Настоящая книга предназначается для широкого круга инженеров (научно-исследовательских институтов, конструкторских бюро, полигонов и заводов), занимающихся определением качества и надежности радиоэлектронной аппаратуры и других массовых изделий промышленности (машиностроения, приборостроения, артиллерийской и т.п.).
В книге дается приложение методов математической статистики к вопросам обработки и оценки результатов испытаний, при которых определяются качество и надежность испытываемых изделий. Для удобства читателей приводятся необходимые сведения из математической статистики, а также большое число вспомогательных математических таблиц, облегчающих проведение необходимых расчетов.
Изложение иллюстрируется большим числом примеров, взятых из области радиоэлектроники и артиллерийской техники.